本文由來
這是一份由 Claude Code 整理的草稿,內容尚未經作者人工審稿,可能有不準確的地方。
整理依據:
- GitHub repo,
youtube-analytics-mcp-server(private repo)的 README(若有)、commit 歷史與原始碼- Codex CLI session(2026-02-05),記錄了 MCP server 實際使用中踩到的 API 坑與後續功能補充
文章開頭的 hero 圖由 Codex CLI 內建的 image_gen 工具生成(OpenAI gpt-image-2 模型)。
起因
我在管理一個 YouTube 頻道,時常需要查影片表現、流量來源、搜尋字詞。過去的做法是,打開 YouTube Studio,點很多層,把數字截圖下來,再貼進 Claude 對話框問分析。
這個流程太繞了。
既然 Claude 支援 MCP(Model Context Protocol),讓 AI 直接透過工具呼叫去拿資料,為什麼不乾脆把 YouTube API 包成 MCP server,讓 Claude 自己去拿資料、自己分析?
這就是 youtube-analytics-mcp-server 的起點。
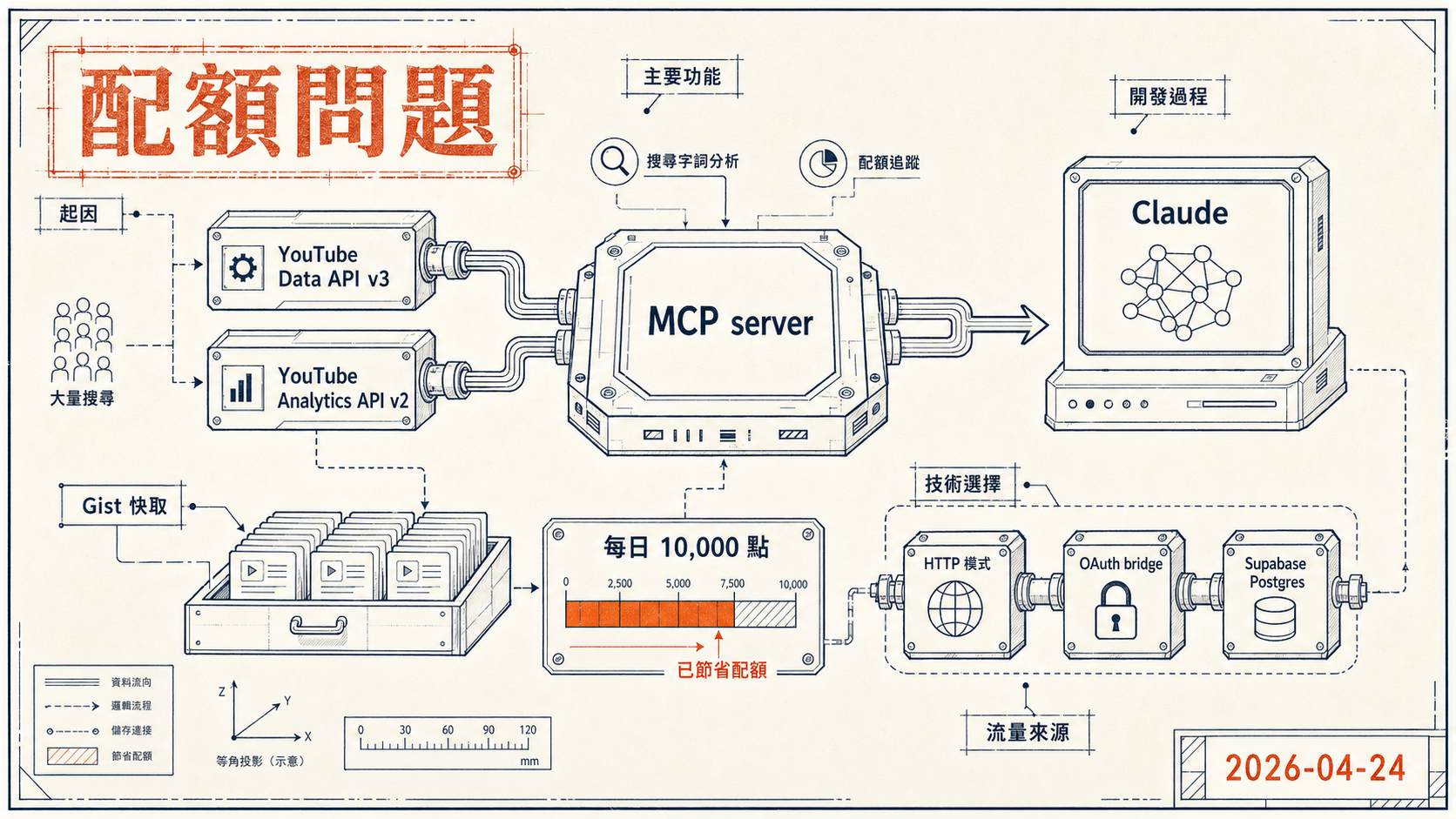
主要功能
這個 MCP server 把 YouTube Data API v3 與 YouTube Analytics API v2 包成一組 tools,Claude 可以直接呼叫。主要功能包含:
- 影片管理,列出、搜尋、讀取影片詳細資料,以及更新標題、描述、標籤、分類
- Analytics 查詢,讀取單支影片或整個頻道的觀看數、留存率、流量來源
- 搜尋字詞分析,看哪些關鍵字帶進流量
- 配額追蹤,即時掌握當日 API 用量,避免超出每日上限
支援兩種運行模式,stdio 模式適合本機開發,直接在 Claude Desktop 的 MCP 設定裡啟動;HTTP 模式 則是把 server 部署到 Render,透過 OAuth bridge 讓 Claude.ai 的 Custom Connector 遠端接入。
開發過程
這個 repo 其實不是從零開始,之前有一個更早的版本(youtube-analytics),只能讀資料,沒有寫入、沒有快取、配額也沒追蹤。用了一段時間後發現功能不夠,才重新做了這個進階版,支援影片標題描述更新、多層快取、配額監控。
最早的版本(Initial commit)只有基本的影片列表和 analytics 查詢,用 stdio 模式跑,OAuth token 存在本機的 .youtube-tokens.json。
後來加了大量搜尋功能,然後發現一個問題,每次問「最近表現最好的影片是哪幾支」,Claude 都會去呼叫 youtube_list_videos,每次都消耗配額,每日 10,000 點很快就用完了。
這時沿用了 ai-video-writer 既有的 Gist 快取模式,把影片清單快取進一個 GitHub Gist,youtube_list_videos 和 youtube_search_videos 優先讀 Gist,API 呼叫只在快取不存在或刷新時觸發。Gist 格式跟 ai-video-writer 共用同一份,讓兩邊資料保持一致。
再後來,我希望能在不同裝置上用 Claude.ai 查,而不是只有本機,所以把 server 改成支援遠端 HTTP 模式,加了完整的 OAuth bridge,讓 Claude connector 透過標準 OAuth 流程授權,Google refresh token 不用暴露在 Render 環境變數裡。最後用 Supabase Postgres 持久化 token,這樣 Render 重啟後 session 不會掉。
在實際使用過程中,也踩到了幾個 API 的坑,促成後續的功能補充。
creatorContentType 問題。最初在週報裡判斷影片是 Shorts 還是長片,agent 用的是片長或標題裡有沒有 #shorts。跑了幾次後發現有些 Shorts 被錯判,原因是 YouTube Data API 回傳的是 categoryId(內容分類,例如「科技」)而不是格式分類,片長也不可靠。正確做法是要用 YouTube Analytics API 的 creatorContentType 維度,YouTube 才會直接告訴你這支是 SHORTS 還是 VIDEO。這個問題在使用中暴露之後,馬上補進了 ANALYTICS_DIMENSIONS 常數並 commit 上去。
analytics filters 與 sort 補強。同樣是在實際查詢中,發現幾個 tools 的參數不夠彈性,沒辦法針對特定影片過濾、也沒辦法排序。於是在 youtube_get_channel_analytics、youtube_get_traffic_sources、youtube_get_search_terms 上都加了 filters 和 sort 參數,讓 Claude 能更精確地組合查詢。
「續看觀眾比率」的 API 限制。YouTube Studio 的 Shorts 頁面有一個「Stayed to watch」指標,顯示一個像 15% 的單一百分比。我以為 API 能拿到這個數字,花了一段時間才搞清楚,這個指標目前沒有對應的公開 API 欄位。API 提供的是 audienceWatchRatio(搭配 elapsedVideoTimeRatio 維度),回傳的是整條留存曲線,不是單一百分比。Studio 顯示的那個數字是 Studio 自己計算的 UI 指標,沒辦法直接從 Analytics API 撈出來。這個限制現在已記錄在 skill 文件裡,避免之後又花時間查。
技術選擇
幾個有趣的決策點值得記錄。
為什麼做成 MCP 而不是直接寫腳本接 API
直接接 API 的腳本,每次問問題都要我手動決定要呼叫哪個 endpoint、傳什麼參數。做成 MCP server 之後,Claude 自己決定要呼叫哪個 tool、怎麼組合多個 tool 來回答問題。問「最近三個月哪支影片的流量來源最多是站外搜尋」這種問題,Claude 會自動拆成多個 tool call,這是手寫腳本很難做到的。
Gist 快取的設計
YouTube Data API 的配額以每日 10,000 點為上限,list 類操作每次消耗 1-100 點不等。Gist 快取把「哪些影片存在」這份靜態資料存進 GitHub Gist,讀取時走 GitHub API(不消耗 YouTube 配額),只有需要即時資料(analytics、留存率)時才打 YouTube API。
另一個細節,Gist 快取刻意不做 in-memory cache,每次都從 GitHub API 重新抓,原因是 MCP server 可能是多個 Claude session 共用,讓 Gist 成為唯一的 source of truth 比較乾淨,也方便其他工具(例如 ai-video-writer)同時寫入更新。
OAuth bridge 而不是直接把 token 塞進環境變數
remote 模式最直觀的做法是把 Google refresh token 放進 Render 環境變數,但這樣有兩個問題,一是 token 洩漏的風險,二是如果 token 失效(例如授權被撤銷),要重新部署才能更新。
OAuth bridge 的做法是讓 server 自己走一次 Google OAuth,拿到 token 後存進 Postgres,之後 Claude connector 拿到的是 server 自己發的 MCP token,Google token 完全不對外。Access token 到期時 server 自動用 refresh token 換新的,並回寫 store。
這套 OAuth bridge 的型別定義(src/types/auth.ts)跟加解密 helper(src/lib/crypto.ts)後來在做 ga4-remote-mcp 時直接整段拿過去用,兩個 repo 同一份 SHA,省下重寫底層的功夫,也讓兩個 MCP server 之間的 token 處理風格保持一致。
心得
(TODO 補上)
結語
這個 server 現在已經是日常工作流的一部分,查頻道表現、找表現差的影片、分析流量來源,全部在 Claude 對話裡完成,不用再跳去 YouTube Studio 翻資料。
MCP 的價值不只是「讓 AI 能存取更多資料」,而是讓 AI 能自主決定怎麼組合資料,回答那些原本要手動拼湊的問題。