本文由來
這篇是 Claude Code 整理
youtube-analyticsrepo 的 README、commit 歷史與原始碼後,由作者審稿發布。補充材料來自 Codex CLI sessions(~/.codex/sessions/)與repo-stories.md的 repo 整理記錄。原始素材建立於 2026/01/06。
文章開頭的 hero 圖由 Codex CLI 內建的 image_gen 工具生成(OpenAI gpt-image-2 模型)。
起因
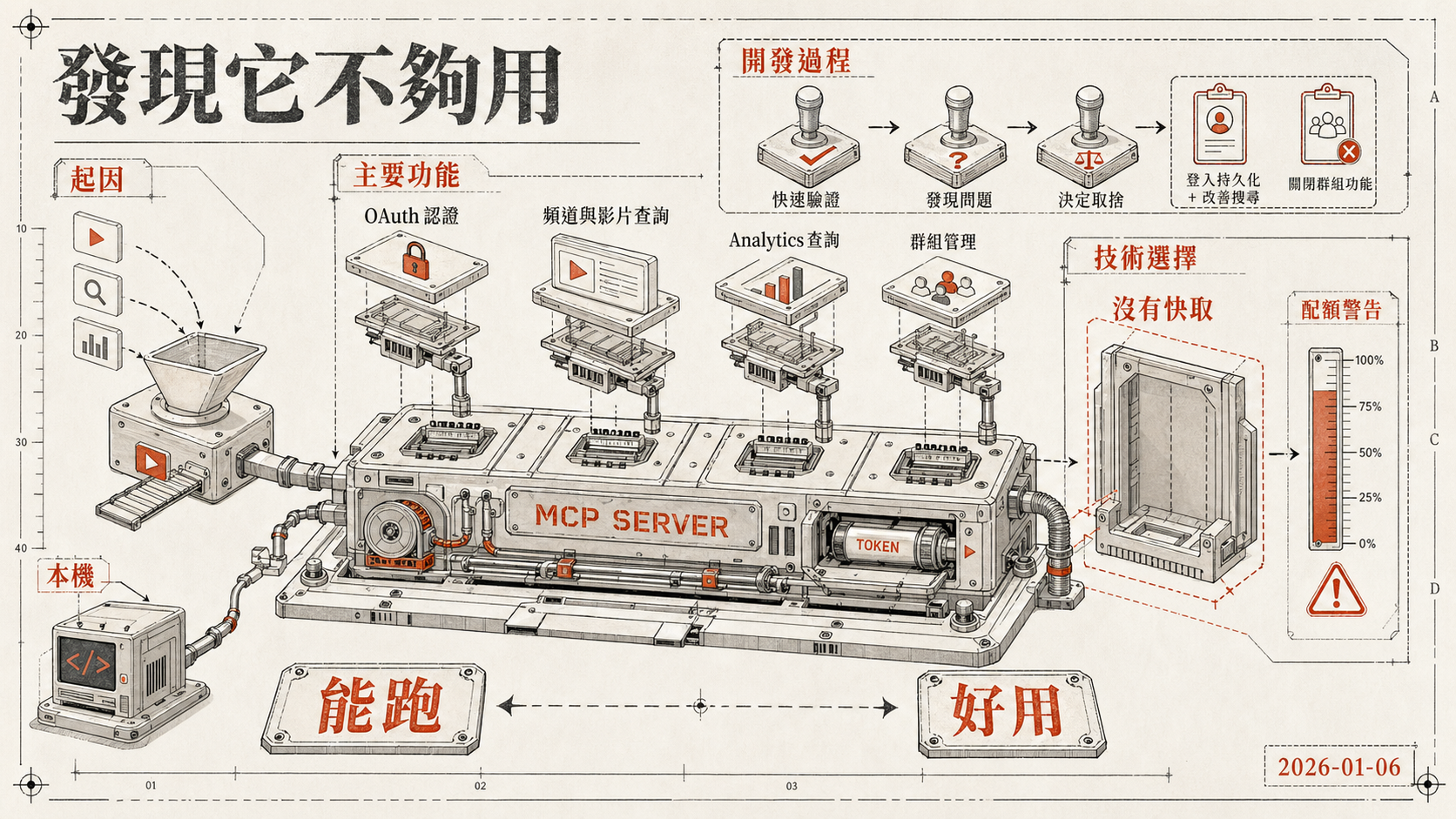
在做 youtube-analytics 之前,我其實已經有一個叫 youtube-analyzer 的 Web 儀表板,是用來查看頻道數據的前端介面。問題是,每次想知道某支影片的留存率或流量來源,還是要先打開儀表板,在不同分頁間切換,把數字截圖下來,再手動貼進 Claude 問分析。
Claude 支援 MCP,理論上可以讓 AI 直接呼叫外部工具拿資料,不需要靠人工中介。YouTube 有官方 API,Google Cloud Console 可以拿到 OAuth 憑證。把這兩件事連起來,用 Claude Code 直接刻,感覺不用太久。
這就是 youtube-analytics 的起點,一個用來驗證想法的快速原型。
主要功能
這個版本用 TypeScript 寫,核心依賴是 googleapis(Google 官方 SDK)和 @modelcontextprotocol/sdk。工具清單如下,
- OAuth 認證,
youtube_get_auth_url產生授權 URL,youtube_authorize完成 token 交換,token 存在本機token.json - 頻道與影片查詢,列出頻道、讀取影片清單和詳細資料
- Analytics 查詢,以彈性的 metrics / dimensions / filters 組合查詢資料,支援 JSON 和 Markdown 兩種回傳格式
- 群組管理,建立、列出、刪除 YouTube Analytics 群組
工具數量不多,但已經覆蓋了我最常需要的查詢場景。
開發過程
Initial commit 在 2026/01/06 落地,是完整的 MCP server 骨架,OAuth 流程、YouTube API 包裝、工具定義都在,群組管理功能也在這一版就有了。
接著補了「登入持久化 + 改善搜尋」,讓重啟 server 後不需要重新跑 OAuth,並讓影片搜尋更好用。然後試著把群組功能關掉(「關閉群組功能」),因為群組 API 有獨立的配額與權限要求,當下判斷不值得增加設定複雜度,又立刻 revert 回來,群組功能最終還是留著。最後一個 commit revert 了「登入持久化 + 改善搜尋」,登入持久化在這版也沒有保留下來。
整個 repo 的 commit history 只有五條,週期不到一天,典型的 vibe coding 節奏,快速驗證、發現問題、決定取捨。
配額的問題在 prototype 還沒跑滿一天就出現了。youtube_list_channel_videos 每次分頁都打一次 YouTube Data API,很快就碰到配額警告。隔天(2026/01/07),我另外做了一個極簡的 youtube-analytics-simple-cache,只抓 videoId 和 title,存到 GitHub Gist,讓查詢可以先走 Gist、不消耗 YouTube 配額。這兩個工具是前後腳完成的,加在一起才算是完整回答了「怎麼讓 AI 查影片資料又不把配額燒光」這個問題。
技術選擇
為什麼從第一版就做成 MCP
直接寫 CLI 腳本也可以拿到 YouTube 資料,但每次問問題都要我手動選 endpoint、組參數。MCP 的好處是讓 Claude 自己決定要呼叫哪個工具、要怎麼組合,問「最近哪支影片的觀眾留存率掉最多」這種問題,Claude 會自動拆成多個 tool call 去拿不同的資料,這是手寫腳本做不到的。
stdio 模式跑在本機
第一版只支援 stdio transport,server 從 Claude Code 的 ~/.claude.json 啟動,config 檔裡直接帶 GOOGLE_CLIENT_ID 和 GOOGLE_CLIENT_SECRET 兩個環境變數。設定方式記在 CONFIG_INSTRUCTIONS.md,連去哪裡改哪個欄位都寫好了,因為這個 config 是讓自己在 Windows 機器上直接跑的。
沒有快取
第一版完全沒有快取設計,每次 Claude 呼叫 youtube_list_channel_videos,就直接打一次 YouTube Data API。YouTube Data API 的每日配額是 10,000 點,list 操作每次消耗不少,很快就遇到配額警告。
這是第一版最明顯的問題,也是後來重新設計的主要原因之一。
心得
做這個 prototype 最大的收穫,不是「MCP 能跑」,而是親身感受到兩件事。
第一,工具的精簡比功能的完整更重要。群組功能的關閉 → revert 這段來回,讓我意識到每多一個 API surface,就多一層配額與權限的複雜度。MCP tool list 越長,AI 在組合呼叫時出錯的機會就越多,設定也越複雜。只留真正常用的 tool,讓 Claude 的判斷空間縮小,反而更可靠。後來在設計 youtube-analytics-mcp-server 的時候,我刻意沒有把所有 YouTube API 的功能都包進去,這個決定就是從這裡來的。
第二,quota 管理從一開始就要考慮,不能留到後期。第一版完全沒有快取,是因為當時想先確認「OAuth 能不能跑通、Claude 能不能拿到資料」這個核心假設。假設確認後,配額問題馬上就出現了,隔天就另外做了 simple-cache。如果一開始就把快取設計進去,prototype 會更慢,但也不會在剛驗證成功的時候立刻碰壁。這是 vibe coding 的代價,也是它的特性,先跑起來,再解決跑起來之後才發現的問題。
結語
youtube-analytics 是一個「能跑」的 prototype,它驗證了把 YouTube API 包成 MCP 這件事是可行的,OAuth 流程通了,Claude 能呼叫工具拿到真實資料,這個核心假設成立。
但「能跑」跟「好用」之間還有一段距離,配額用完的問題、只能在本機跑的限制、群組功能的去留,這些都是後來重新設計時處理的事。
後續的演進版本記在 用 MCP 把 YouTube Analytics 接進 Claude,順便解決 API 配額問題,包含 Gist 快取設計、遠端 HTTP 模式、OAuth bridge 和 Supabase token 持久化。這篇算是那篇的前傳。