本文由來
這篇是 Claude Code 根據 GitHub repo
youtube-analytics-simple-cache的 README、commit 歷史與原始碼整理的開發記錄,經作者審稿後發布。文章開頭的 hero 圖由 Codex CLI 內建的 image_gen 工具生成(OpenAI gpt-image-2 模型)。
起因
在做 YouTube 頻道後台工具的時候,有個需求很常見,就是「讓使用者在前端用關鍵字搜尋自己的影片」。
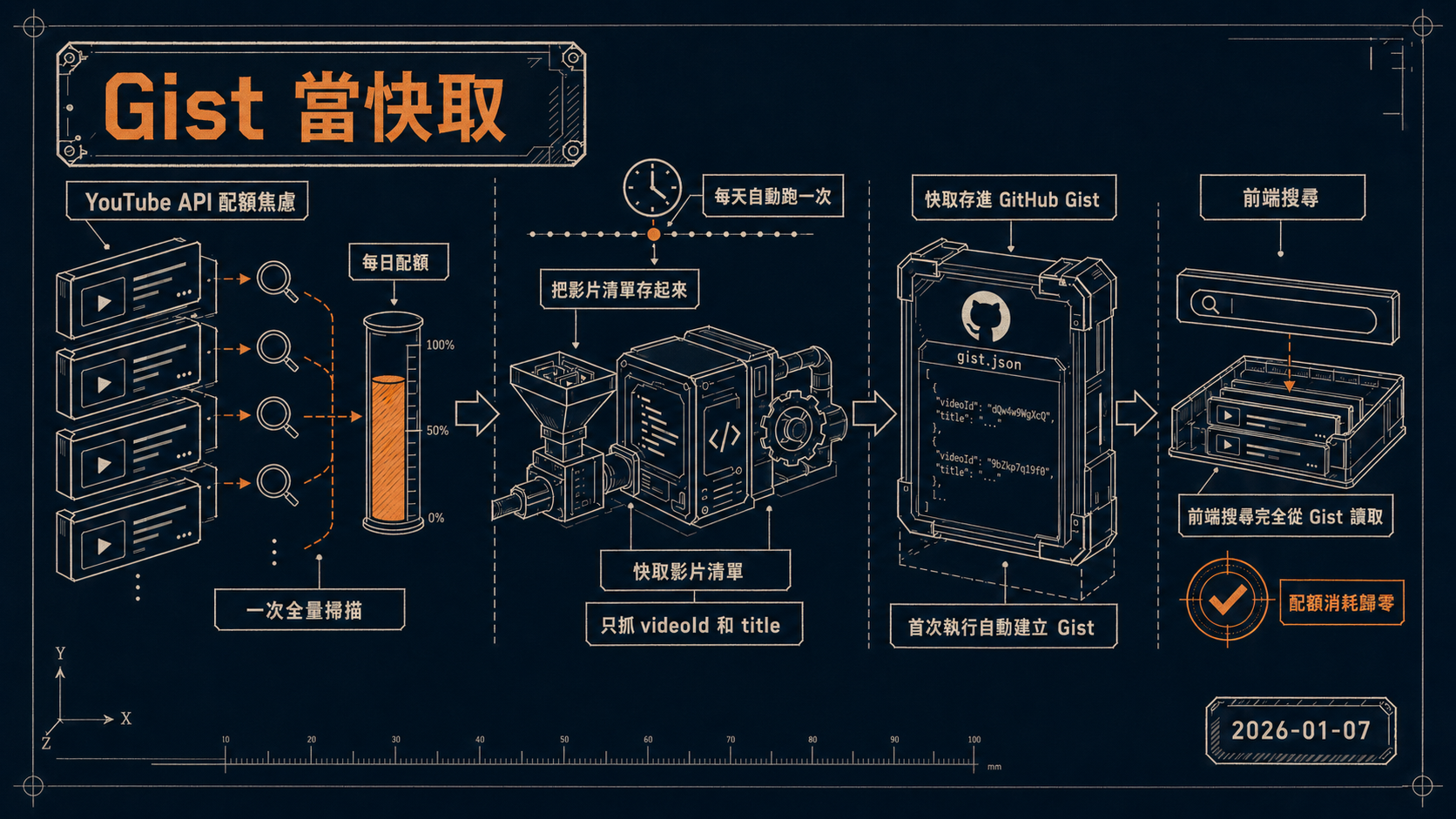
第一個直覺是直接打 YouTube Data API,輸入關鍵字,拿回結果。問題是 YouTube API 的每日配額只有 10,000 點,而一次 search.list 就要消耗 100 點。如果頻道有 1,500 支影片、分 30 頁取完,一次全量掃描就燒掉 3,000 點,佔單日配額的 30%。
更慘的是,如果前端每次搜尋都打 API,那配額根本撐不住一個早上。
這個問題在做 YouTube Analytics MCP Server 的時候特別明顯。MCP 讓 Claude 可以直接呼叫 YouTube API 查資料,用起來方便,但正因為查詢太方便了,配額反而消耗得更快。在 2026 年 1 月初的開發過程中真實碰到這個天花板,才決定把快取這件事單獨拉出來解決。
解法不難,但要繞個彎,「把影片清單存起來,讓前端搜本地資料就好」。
主要功能
youtube-analytics-simple-cache 是一個輕量工具,核心很簡單。
- 只抓 videoId 和 title,不多抓觀看數、標籤等欄位,壓低 Gist 檔案大小
- 每天自動跑一次,透過 GitHub Actions 排程,不需要跑 API server
- 快取存進 GitHub Gist,前端直接從 Gist raw URL 讀取,完全不消耗 YouTube API 配額
- 首次執行自動建立 Gist,後續更新同一個 Gist,Gist ID 存在 GitHub Secrets 裡管理
快取格式長這樣,乾淨到不能再乾淨。
{
"version": "1.0",
"updatedAt": "2026-01-07T08:40:00.000Z",
"totalVideos": 1500,
"videos": [
{ "videoId": "abc123", "title": "影片標題" },
{ "videoId": "def456", "title": "另一個影片" }
]
}1,500 支影片大約只佔 75 KB,遠低於 Gist 的 10 MB 上限。
開發過程
這個 repo 從 ai-video-writer 專案裁剪出來,原本的版本功能比較多,這次只保留「快取影片清單」這條線。ai-video-writer 裡早就有 GitHub Actions 排程加上 Gist 快取的機制,算是把這個模式從大 repo 裡抽出來獨立成一個可以直接 clone 使用的小工具。
開發時最花時間的不是邏輯本身,而是 OAuth token 的處理。YouTube API 需要 OAuth 2.0,access token 短暫有效,每次執行前都要先用 refresh token 換一個新的。這段流程在 Actions 裡跑沒有問題,但要讓 CI 環境也能用,就得把 YOUTUBE_CLIENT_ID、YOUTUBE_CLIENT_SECRET、YOUTUBE_REFRESH_TOKEN 全部存進 GitHub Secrets,啟動時再注入環境變數。
Gist 的部分也有一個小細節,第一次執行時 Gist 還不存在,腳本會自動呼叫 POST /gists 建立,之後就用 PATCH /gists/:id 更新同一個。GIST_ID 第一次先留空,Actions 執行完後從 log 裡複製 ID 回填到 Secrets,之後就全自動了。
整個 repo 只有 3 次 commit 就收工,這個數字有點說明問題,因為功能是從已驗證的程式碼裁剪出來的,不需要重新探索。設計決策已經在 ai-video-writer 裡跑過一輪,這裡只是把必要的部分留下來。
為什麼只抓 videoId 和 title
有一個設計選擇值得解釋一下。這個工具刻意只抓兩個欄位,觀看數、標籤、發布時間、縮圖 URL 全部不要。
原因是快取的目的就是「讓前端搜尋影片」,而搜尋只需要 title。videoId 是為了把搜尋結果連回 YouTube 原始頁面,除此之外不需要其他資料。欄位越少,Gist 檔案越小,前端 fetch 越快,每次更新消耗的 API 配額也越省。
如果需要觀看數等詳細資料,在搜到影片之後用 videos.list 個別查就好,那時候只查一支影片,配額消耗是 1 點,不是 100 點。
技術選擇,為什麼是 Gist 加 Actions
有幾個替代方案當時也考慮過。
方案一,直接存進 repo。Actions 把 JSON commit 回 repo,前端從 raw GitHub 讀。這樣做沒問題,但每天一個 commit 會讓 git log 很吵,而且 commit 的時間點不好控制。
方案二,用 S3 或 R2。功能上沒問題,但要多開一個雲端服務帳號、設定 bucket、管 key,對這個小工具來說太重了。
Gist 的優點剛好符合這個場景,免費、有 raw URL 可以直接 fetch、不需要額外服務、PATCH 更新很容易、GitHub Personal Access Token 只要勾 gist 一個權限就夠。
Actions 的排程用 cron 設在台灣時間每天 22:40 執行(UTC 14:40),一天消耗約 3,000 點配額,剩下 7,000 點留給其他操作,配額壓力幾乎消失。前端搜尋完全從 Gist 讀取,配額消耗歸零。
整體架構就是,Actions 定時跑 Node.js 腳本,腳本呼叫 YouTube API 分頁抓完整影片清單,整理成 JSON 後 PATCH 上 Gist,前端從 Gist raw URL 讀快取,在本地做 filter 搜尋。
前端的整合很直觀,
const response = await fetch('https://gist.githubusercontent.com/username/gist_id/raw/youtube-videos-simple-cache.json');
const cache = await response.json();
const keyword = '關鍵字';
const results = cache.videos.filter(v =>
v.title.toLowerCase().includes(keyword.toLowerCase())
);一次 fetch,之後所有搜尋都在本地跑,配額消耗歸零。
心得
這個工具規模不大,但反映了一個思路,就是「先確認需求的最小公分母,再決定要存什麼」。
很多開發者在設計快取的時候,會習慣把所有欄位都存起來,「以後可能用到」。但 Gist 的 raw URL 是公開的,如果存了影片的私人狀態、觀看數等敏感數據,曝露風險就上來了。而且每次 Actions 跑完都要全量更新,欄位越多,每次 API 呼叫消耗的配額就越多。
只存 videoId 和 title,既降低了 Gist 大小,也讓配額消耗最小化,前端的 filter 搜尋也夠用。更重要的是,這個快取格式幾乎不需要維護,不會因為 YouTube API 增加了新的欄位就要更新 schema。
另一個觀察是,Gist 作為輕量靜態快取的使用場景被嚴重低估。它免費、有 raw URL、PATCH API 很簡單、只需要一個 gist 權限的 Personal Access Token。如果你的資料符合「不需要即時性、每天更新一次就夠、資料量在幾十 KB 以內」這三個條件,Gist 往往比自建 API 或開雲端儲存 bucket 划算得多。
結語
這個工具解決的問題很具體,YouTube API 配額有限,但影片清單不需要即時性,每天同步一次就夠。用 Gist 當靜態快取、用 Actions 當排程器,幾乎零成本就把問題繞開了。
如果你也有 YouTube 頻道,需要在自己的工具裡做影片搜尋,這個架構值得參考。