本文由來
這是一份由 Claude Code 與 Codex CLI 整理的草稿,內容尚未經作者人工審稿,可能有不準確的地方。
整理依據:
- GitHub repo
storyboard-system(private repo)的 README(若有)、commit 歷史與原始碼- Claude Code 工作 session 紀錄,
~/.claude/projects/-Users-jaschiang-GitHub-storyboard-system/- Codex CLI session 紀錄,
~/.codex/sessions/(2026/03 與 2026/04 的 storyboard-system sessions)文章開頭的 hero 圖由 Codex CLI 內建的 image_gen 工具生成(OpenAI gpt-image-2 模型)。
起因
在 Vibe Coding 工具盤點 那篇,我有提到分鏡圖系統排在第五個。這篇是更深入的單篇紀錄。
做這個工具的起因很直接,我需要拍短影音,但每次從「想法」到「能給製作方看的分鏡腳本」之間,都要花掉大量時間。傳統流程是先寫文字腳本、再手畫或用 Figma 排分鏡、再找人生成圖,光這段就很耗神。
所以我想用 AI 把這條管線接起來,輸入「這支影片要拍什麼」,剩下的讓工具幫我處理。
主要功能
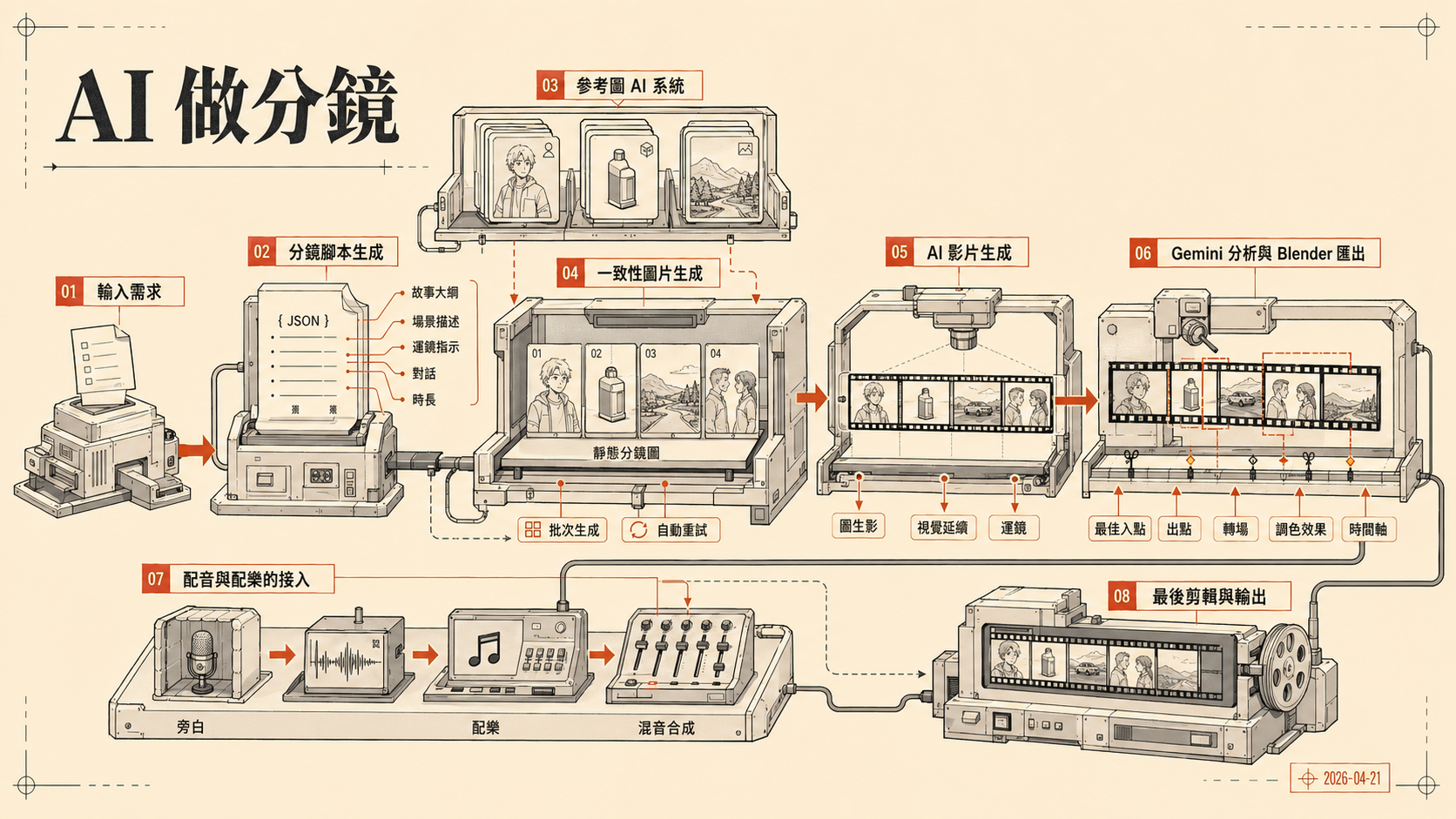
系統分成四個階段,對應專案的四個頁面。
階段一,分鏡腳本生成
透過 OpenRouter 呼叫 Claude Sonnet,輸入故事大綱後生成結構化的 JSON 分鏡腳本。每個鏡頭包含場景描述、運鏡指示、對話、時長,以及 renderLane、productionRisk、deliveryIntent 等 production-ready 欄位。
比較特別的是參考圖 AI 系統,可以上傳角色、商品或環境圖,AI 會自動識別並在生成提示詞時注入 <CharacterName> 標籤,確保整部影片的角色外觀一致,不會因為 prompt 措辭不同就跑偏。
階段二,一致性圖片生成
透過 fal.ai 逐場生成靜態分鏡圖,目前主力是 GPT Image 2,另有 Nano Banana Pro 和 Seedream 5.0 Lite 可選。支援 Image-to-Image,可以把參考圖直接帶進去做風格固定。支援 16:9、9:16、1:1 三種比例與 1K/2K/4K 解析度,批次生成並內建自動重試。
階段三,AI 影片生成
目前接了兩個模型,Kling 2.6 Pro 和 Seedance 2.0,都走圖生影(Image-to-Video)確保鏡頭間的視覺延續。Kling 和 Seedance 各自也有 reference-to-video 模式,可以直接把多張角色參考圖一起送進去生影片。內建 20+ 種運鏡與動作提示詞輔助,包含 Zoom、Pan、Tilt 等常見鏡頭語言。
階段四,Gemini 分析與 Blender 匯出
這段是整個流程的尾聲。用 Gemini 分析生成的影片,自動標記每個鏡頭的最佳入點與出點,並建議轉場和調色效果。接著輸出一份 Blender 5.0 的 Python 腳本,執行後自動把所有素材組裝到 VSE(Video Sequence Editor)時間軸,加好轉場,連算圖都可以 headless 跑。
開發過程
整個系統是用 Vibe Coding 方式建的,也就是用 Claude Code 輔助開發,大部分程式碼由 AI 生成,我負責定義需求、驗收行為、調整架構方向。
從 commit 記錄可以看到幾個明顯的演化脈絡。
圖片生成模型的更替
早期主力是 Fal AI 的 nano banana pro,在開發過程中換成了 GPT Image 2(透過 fal.ai 的 openai/gpt-image-2 端點呼叫,不是直接打 OpenAI API)。這個決策有個小插曲,我當時問 Claude 說「GPT Image 2 官方承認跨 session 會 drift,這條打不贏 nano banana pro 嗎」,結果 Claude 引用了一篇 apidog 的第三方文章,被我逼問出處後才承認來源不是官方,查了 OpenAI Cookbook 才確認正確的做法。後來乾脆在 code 裡做了 VISIBLE_IMAGE_MODELS 白名單,把 nano banana pro 預設隱藏,沒有特別指定一律走 GPT Image 2。
GPT Image 2 有個和 nano banana pro 不一樣的參數系統,不是填 width/height 就好,而是要符合「邊長是 16 的倍數、長邊不超過 3840、長寬比不超過 3:1」這些限制,超出去 fal 的 API 會直接回 422。後來寫了一個 toGptImage2ImageSize() 函式統一換算,把 aspectRatio(16:9、9:16、1:1)加 resolution(1K/2K/4K)的組合自動轉成合法的像素尺寸。
角色庫的一致性踩坑
這是整個系統裡最反覆調整的部分。
最初的做法是上傳角色的多個視角(正面、側面、四分之三等),每張圖上傳的時候各自呼叫一次視覺模型分析,生成各自的 identityCore 和 mustKeepFeatures。問題是,每次分析都是獨立的,Gemini 沒辦法跨視角對照,導致正面視角說「左眼藍色、右眼綠色」,四分之三視角描述出來的左右就搞反了。角色庫裡如果同時有角色的 5 個視角加商品的 2 個視角,湊起來就是 7 張參考圖,觸發了「超過 3 張衝突 reference」的邏輯,反而什麼都送不進去。
後來的解法是把分析流程改成批次單次呼叫,所有視角一起送進 Gemini,讓它一次輸出一份 canonical 身份描述,per-view 的角度差異另外補充。同時把 identityCore 和 mustKeepFeatures 從每個 view 裡面提升到 CharacterLibraryItem 的頂層,後續生成時優先讀頂層的 canonical 版本,向下相容舊資料。
另一個坑是提示詞裡的 CJK 文字曾經被 hard filter 靜默丟掉,因為某段程式碼假設 identityCore 一定是英文。加了一道翻譯層,中文描述先翻英文再注入,翻不了就 fallthrough 直接用原文。
影片生成的 reference-to-video 切換
影片生成一開始只有「起幀圖生影片」,就是先生靜態分鏡圖,再把圖餵給 Kling 2.6 做 image-to-video。後來接了 Seedance 2.0 ref 和 Kling O1 reference-to-video 模式,差別在於可以直接把多張角色參考圖一起送進去,不需要先有一張分鏡圖,模型自己從 reference cluster 推斷視覺一致性。Seedance 2.0 的 reference 模式最多接 9 張圖片,Kling O1 最多 7 張。
切換過程中我問了一句「為什麼你不是用 reference 跑?」才發現某個生成路徑根本沒走到 reference 模式。翻了程式碼才確認,reference 模式需要明確傳 referenceImageUrls,但當時的 UI 沒有把 scopedRefs 收集進去。
提示詞的結構也調整過,Seedance 的最佳實踐是「不要描述圖裡已經看得到的靜態外觀,只描述應該怎麼動」,這和圖片生成的邏輯完全反過來。圖片生成要把角色描述得越詳細越好,影片生成如果還在提示詞裡重複描述外觀,反而會干擾模型,浪費 token。
一致性驗證器的加入
跑了幾個真實專案之後,我發現純靠眼睛看結果是否一致太慢了,特別是批次生成十幾個鏡頭的時候。於是加了一個 SceneConsistencyReport 型別,每個 scene 可以掛一份機器分析報告,用 Gemini 對生成結果和原始參考圖做比對,輸出 pass / warn / fail 分級加差異描述。這個設計讓工程層面可以加 blocker,強迫你在出錯的鏡頭修好之前不能繼續生後面的影片。
晚期的迭代還集中在工程品質補強,引入 structured API error envelope、LLM usage log、API 路由統一的 error 處理。這些對 vibe-coding 出來的系統格外重要,因為 AI 生成的程式碼往往在 error handling 最隨便,要另外花力氣補。
腳本「吸引力」的前置設計化
做了幾輪實際測試之後,我發現一致性只解決了「不漂移」,但沒解決「有沒有人想看」。原本的 second-pass 修正器只檢查合理性和視覺一致性,幾乎不看觀看吸引力,所以腳本容易穩但平。
解法是在 Scene schema 加入 hookScore(1-5)、hookScoreReason、retentionRisk,以及場景級的 referencePlan,讓模型在第一輪就輸出這些欄位,second-pass 也改成會檢查「開場第一鏡是否有明確 Hook、中段有沒有留存節奏、結尾是否收得住」。這樣吸引力變成前置設計,而不是生完再評。
同時補了一個 referencePlan 解析器,把原本散落在 charactersUsed、requiredReferences、referenceViewHints 的資訊收斂成一份場景級的已解算計畫。這樣圖片生成和影片生成才不會各自猜一次,而是讀同一份場景意圖。這個設計上的靈感來自研究 Jellyfish 專案時的收穫,它把一致性問題拆成「全域資產庫、專案快照、跨分鏡參考圖、提示詞模板」幾層的思路,讓我確認自己缺的是場景層面的 reference 治理,而不是再加一個角色庫頁面。
配音與配樂的接入
影片生成之後,系統接了兩條音訊管線,分別走不同服務。旁白用 IndexTTS2,配樂用 ElevenLabs。兩者都是在分鏡腳本生成之後才能配,因為要對準影片時間軸。音訊生成走主系統的 Next.js app(port 5100)API 路由呼叫,fluent-ffmpeg 負責最後的混音合成,把旁白、配樂、原始影片素材合成為最終輸出。external/openreel-video 子服務(port 5173)是分開啟動的時間軸剪輯介面,主要用在最後一步的手動精剪與匯出。
技術選擇
技術選型對齊我慣用的 stack,沒有為了新穎而新穎。
| 層次 | 選擇 | 原因 |
|---|---|---|
| 框架 | Next.js 15 + App Router | API Routes 與前端同 repo,本機跑不需要部署 |
| 語言 | TypeScript 5 | 複雜的 JSON 結構需要型別保護 |
| 狀態 | Zustand + LocalStorage | 簡單、持久化不需要後端 |
| 資料庫 | SQLite (better-sqlite3) | 本機工具不需要雲端 DB |
| AI 圖片 | @fal-ai/client SDK | 官方 SDK 的 error handling 比直接打 REST 好處理 |
| AI 影片 | Fal AI (Kling / Seedance) | 目前品質與價格的平衡點 |
| 腳本 | OpenRouter → Claude | 彈性切換模型,不綁死單一 provider |
| 影片處理 | fluent-ffmpeg | 本機音軌合成、旁白混音 |
| 旁白 | IndexTTS2 | 分鏡腳本生成後配音,走主系統 API 呼叫 fal.ai |
| 配樂 | ElevenLabs | 與旁白分開管線,同樣走主系統 API |
LocalStorage 做持久化這件事,算是 vibe-coding 工具的典型選擇,因為部署成本為零。但資料量一大就需要考慮遷移,這個系統後來加了 SQLite 就是因為專案多了之後 localStorage 開始不夠用。
圖片模型的選擇上,GPT Image 2 和 nano banana pro 的核心差異在於,GPT Image 2 有語意理解能力,可以根據文字指令做 inpainting(mask 合成),nano banana pro 則在 4K 原生解析度和更寬的長寬比支援上有優勢。實際用下來,GPT Image 2 的 reference 模式在多角色、多商品同框時表現更穩,成為主力選擇。
借力其他專案
這個系統很多地方不是自己從零寫的,而是把開源社群的東西組起來再加上自己的工作流。
Augani/openreel-video(MIT),整個瀏覽器內的影片剪輯引擎是直接 bundle 在 external/openreel-video/ 子資料夾下,當作獨立子服務啟動(port 5173)。OpenReel 自稱是「open source CapCut alternative」,130k+ 行 TypeScript,跑在純 client side,多軌時間軸、轉場、effects、音訊混音都有,比起自己刻一個剪輯 UI,直接借這套是最務實的選擇。我這邊主要把它當「最後合成階段」的編輯介面,前面的 AI 腳本/分鏡/生圖都是自己的程式跑完之後,把素材丟進 OpenReel 做最後剪輯與輸出。
Forget-C/Jellyfish,一個一站式 AI 短劇生產工具,研究它的時候對我影響最大的是它把一致性問題拆成「全域資產庫、專案快照、跨分鏡參考圖、提示詞模板」幾層的思路。讓我意識到自己缺的不是再加一個角色庫頁面,而是場景層的 reference 治理,後來把這個思路落地成 referencePlan 解析器(前面 ### 腳本「吸引力」的前置設計化 段有提到)。
songguoxs/seedance-prompt-skill 與 YouMind-OpenLab/awesome-seedance-2-prompts,做 Seedance 影片提示詞時的兩個主要參考來源。前者把 Seedance 提示詞包成一個 Codex skill,後者是社群整理的 awesome list。我自己的提示詞模板大量參考這兩邊的 pattern,特別是「鏡頭運動 + 主體狀態 + 環境光線」三段式描述的順序與用詞。
X (Twitter) 截圖與設計參考,整個專案 Claude Code session 裡累積有 100+ 張 user 上傳的圖片,多半是行內人的 X 貼文截圖(Sora、Veo、Seedance、Nano Banana 等模型實測心得)、其他人做的分鏡 demo、影片廣告片段等。這類「先看別人怎麼做」的 reference-driven 開發在 vibe coding 一個生成式系統時特別重要,因為這領域變化太快,論文跟不上實作,多數最佳實踐都散落在社群討論裡。
心得
這個系統在 vibe-coding 的脈絡下有一個有趣的現象,AI 幫你生出來的程式碼本身就是在生 AI 的 prompt,所以你在 debug 的時候,有時候不確定是「程式碼的問題」還是「prompt 的問題」還是「模型這次跑歪了」。這三層同時在動,很難切開。
我的做法是盡量把 prompt 結構化,把固定的部分(角色描述、場景設定)和動態的部分(鏡頭指示、動作)分開管理,讓每次迭代可以只改一層,其他層不動。這不是什麼特別高深的原則,但在一個多模型的複雜系統裡,這個紀律很容易因為「先湊合跑起來」就放棄,後來再補很麻煩。
另一個心得是,fal.ai 的佇列在高峰期可以排到 1400 號,throughput 大約每分鐘 18-25 張,所以批次生成的等待時間完全不可預期。系統裡做了自動重試和進度輪詢,但用體驗上還是要能接受「送出去,等一下回來看」的節奏,而不是「點下去立刻有結果」。
結語
storyboard-system 目前對我來說是一個「堪用但還在演化」的狀態,整條管線從腳本到初剪都能跑,但每個環節還有很多可以打磨的地方。
最大的收穫不是工具本身,而是在建這個工具的過程中,對 AI 影片生成管線的邏輯有了更直接的理解,哪些環節 AI 擅長、哪些需要人工介入,寫在文件裡遠不如自己做一遍來得清楚。