本文由來
這是一份由 Claude Code 整理的草稿,內容尚未經作者人工審稿,可能有不準確的地方。
整理依據:
- GitHub repo,JasChiang/seo-content-generator 的 README、commit 歷史與原始碼
- Codex CLI 開發 session 紀錄(2026/01)
文章開頭的 hero 圖由 Codex CLI 內建的 image_gen 工具生成(OpenAI gpt-image-2 模型)。
起因
做內容 SEO 有一個讓人很煩的環節,就是找題目。
每隔一段時間就要打開 Google Search Console,看哪些關鍵字曝光高但點擊率低、哪些查詢已經有排名但沒有對應的文章、哪些長尾字在搜尋但平台根本沒寫過,然後把這些整理成一份清單,再交給人去寫。
整個流程很機械,卻很耗時間。於是就想,能不能把這件事自動化,讓工具幫我找,AI 幫我打草稿,人只要做最後的審稿和發布?
這個工具就是這樣誕生的。
主要功能
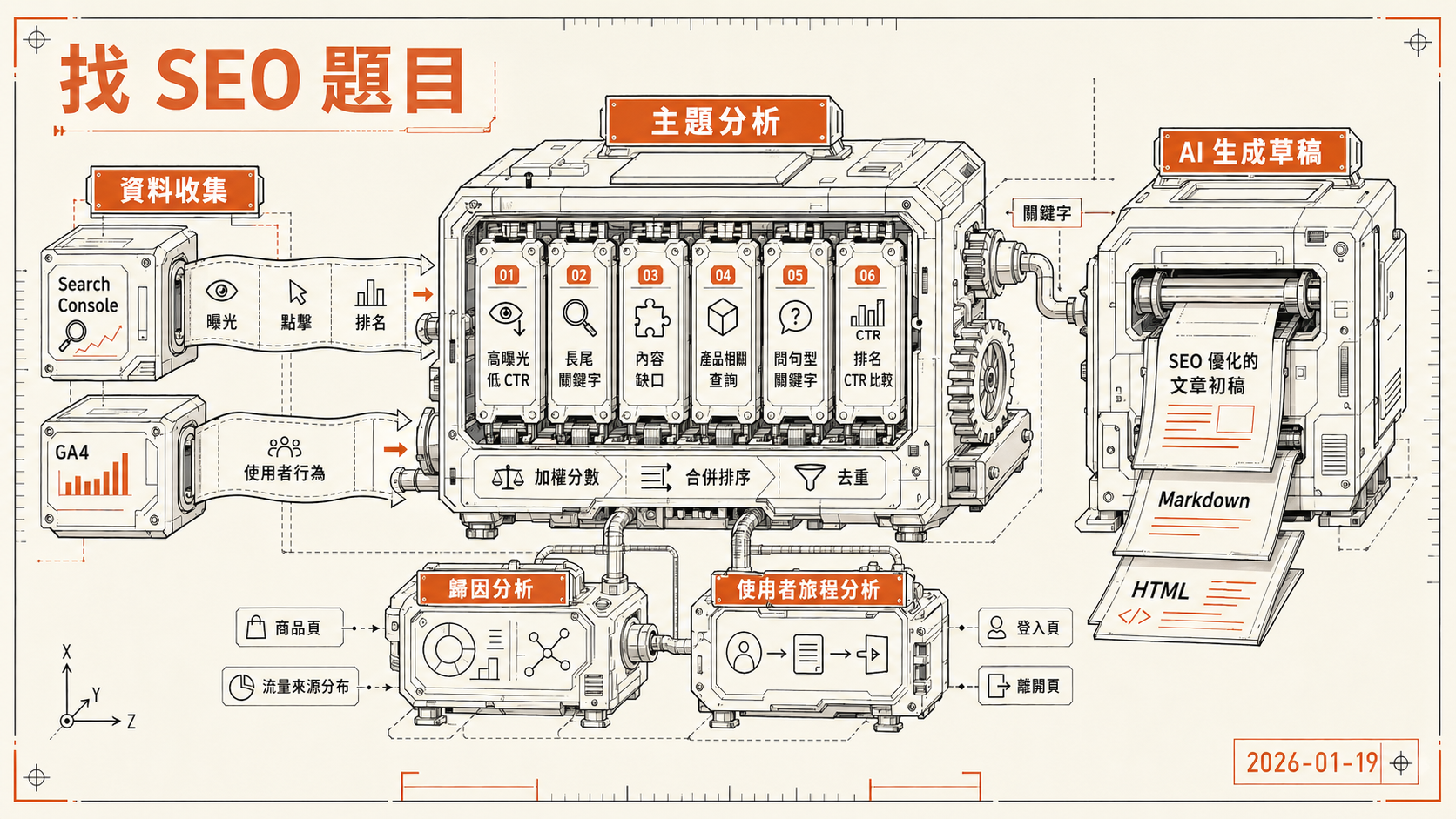
工具的核心流程分三段,串在一起跑。
第一段,資料收集。 透過 Google OAuth 2.0 登入後,工具同時拉 Search Console 和 GA4 兩個資料來源。Search Console 提供關鍵字的曝光、點擊、排名資料,GA4 則補充使用者行為,幫助判斷哪些關鍵字帶來的流量後來有繼續互動。
第二段,主題分析。 這是工具的主要邏輯。總共有六種分析策略可以選,每種對應不同的 SEO 場景。
- 高曝光低 CTR,已經有排名但標題或內容沒吸引到人點進來
- 長尾關鍵字,搜尋量小但意圖明確,比較容易排上去
- 內容缺口,有搜尋量但內容平台沒有對應頁面
- 產品相關查詢,使用者在找特定類型的商品或服務
- 問句型關鍵字,適合做 FAQ 類型的內容
- 排名 CTR 比較,對比同排名的業界 CTR 基準來找出異常
每個策略都有一個加權分數(STRATEGY_WEIGHTS),讓不同策略的建議可以合併排序,不會每次都被同一種策略的結果洗板。
第三段,AI 生成草稿。 選好關鍵字後,透過 OpenRouter API 把題目丟給 LLM,讓它寫出一篇 SEO 優化的文章初稿。模型可以選,預設推薦用 Perplexity Sonar Pro,因為它有即時網路搜尋能力,不容易寫出過時的內容。
生成的草稿存在系統裡,可以在瀏覽器上直接編輯,確認後匯出成 Markdown 或 HTML。
後來又加了兩個延伸分析模組。一個是歸因分析,追蹤「讀者從哪篇文章進來、後來有沒有走到商品頁或產生轉換」,幫助判斷哪些文章真的有帶貨價值。另一個是使用者旅程分析,可以用文章標題或路徑搜尋單篇文章,看到它的流量來源分布、登入頁與離開頁,方便診斷個別文章的問題。
開發過程
從第一個 commit 到基本功能跑起來,兩天 7 個 commit,過程比想像中快,但有幾個卡點值得記一下。
Google API 授權比想像中麻煩。 OAuth 2.0 的設定流程不複雜,但 token 過期後的自動重新授權需要額外處理。後來加了憑證過期偵測,在 session 失效時引導使用者重新登入,這才讓整個流程順起來。
GA4 的 API 和舊的 Universal Analytics 差異很大。 landingPage 維度的追蹤方式改了,要用 landingPage 加上 pageReferrer 兩個維度搭配才能正確追蹤內容助攻轉換,這個問題踩了一個下午。
主題分析的「去重」是個設計重點。 六種策略同時跑,同一個關鍵字可能在不同策略下都出現。最後用 keyword 做 key,只保留分數最高的那筆,避免清單被重複項目塞滿。
Python 版本和 protobuf 衝突。 最初選 google-analytics-data 0.18.2,在 Python 3.13 本機環境上跑到 protobuf 6.x 時報了 “Metaclasses with custom tp_new are not supported” 錯誤,GA4 API 完全呼叫不了。升到 0.20.0 才解決,Render 部署則鎖在 Python 3.9(runtime.txt),確保 library 組合的穩定性。這類 “library 組合地雷” 很難靠文件預測,只能碰壁了才知道。
Render 部署的 SQLite 陷阱。 用 Render 免費方案跑時,才發現它的 filesystem 是 ephemeral 的,每次重啟後 SQLite 資料庫都會清空。開發測試階段無感,但一上正式環境馬上踩坑。最後加了切換 PostgreSQL 的文件說明,讓有需要的人知道怎麼遷移。
部署選了 Render,用 render.yaml 做自動部署,把 build command 和環境變數都定義好,推到 GitHub 就自動上線,維運成本很低。
技術選擇
| 層次 | 選擇 | 理由 |
|---|---|---|
| Web 框架 | Flask 3.0 | 輕量,路由清楚,適合快速做出功能 |
| 資料庫 | SQLite(可換 PostgreSQL) | 內部工具初期不需要多實例 |
| AI | OpenRouter API | 一個 key 可以切換 Perplexity / Claude / GPT-4o |
| 部署 | Render | 免設 infra,git push 即部署 |
| 前端 | Bootstrap 5 + Jinja2 | 不需要 SPA,server-side render 夠用 |
用 OpenRouter 而不直接打各家 API 是一個關鍵決定。SEO 文章生成最適合的模型和一般對話不一樣,有時候需要 Perplexity 的搜尋能力,有時候需要 Claude 的寫作品質,能在同一套程式碼裡切換模型省了很多工。
心得
開發這個工具最大的收穫,是把一個原本「靠人工判斷」的流程拆解成可以程式化的邏輯。找 SEO 題目這件事乍看像是直覺判斷,但仔細拆開來,每一步都有明確的資料依據。哪些字曝光高但沒人點,哪些字有搜尋量但沒文章,哪些字排名比應有的 CTR 低,這些都可以從數字算出來。
AI 生成草稿的部分,我對 Perplexity Sonar Pro 的即時搜尋能力印象不錯。一般 LLM 寫 SEO 文章容易用訓練資料裡的舊資訊,但 Sonar Pro 會先搜尋再生成,在寫「最新旗艦手機比較」或「現在怎麼辦 XX 手續」這類時效性內容時,品質明顯比較可靠。
另一個體會是,Prompt 外掛化值得早做。我把 system prompt 放進獨立的 prompts.yaml,之後調整語氣、字數、格式要求都不用動 Python 程式碼,改完直接重啟就生效,維護比寫死在程式裡輕鬆很多。
結語
這個工具解決的是一個「明明可以自動化,但沒人去做」的問題。找 SEO 題目這件事,邏輯清楚、規則固定,非常適合讓程式代勞。
實際跑起來後,最大的感受是,AI 生成的草稿品質差異很大,取決於給的關鍵字夠不夠精準。 分析策略找出來的關鍵字品質越好,最後生成的草稿就越省力,人工審稿的時間也越短。整個工具的價值,其實更多在前段的「找題目」,而不是後段的「生文章」。
後續想做的功能還有幾個,包括接 WordPress API 直接發布、排程定期自動分析,以及競爭對手關鍵字比較。